
統計的仮説検定は、標本の統計量を元に、母集団に関する仮説を検証するための統計学の手法です。例えば、「日本人の平均身長は170cmである」という仮説を、無作為抽出した100名の身長から検証することができます。そこで今回は、仮説検定を使って、HTTP/2 と HTTP/1.1 の表示速度に、はたして違いはあるのか?を検証してみました。
この記事を書くのにあたって 『「HTTP vs HTTPS Test」(www.httpvshttps.com) の主張を検証する - Webサイトパフォーマンスについて』を参考にさせて頂きました。後半にとてもためになることが書かれています。
結論
記事が長くなりましたので先に結論です。
今回計測した環境の、計測値と仮説検定の結果を見る限りでは「HTTP/2 と HTTP/1.1 の表示速度には違いがあり、HTTP/2の方が速い」が結論です。ただし、サーバとクライアントのネットワークが極端に近い場合は、表示速度に違いはほとんどありません。
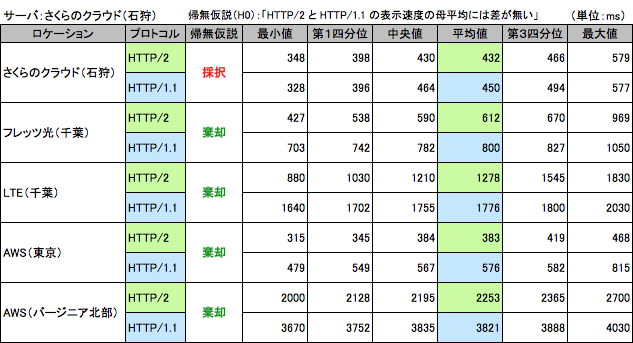
計測値のサマリー
仮説検定の準備
検定方法
「HTTP/2の表示速度の母平均と、HTTP/1.1の表示速度の母平均に違いはあるか」を仮説検定します。それぞれの分散の推定値が一致するとは考えづらく、対応のない2つの平均値の差の検定ですので「Welch(ウェルチ)の検定」を使うことにします。
帰無仮説と対立仮説
帰無仮説(H0):「HTTP/2 と HTTP/1.1 の表示速度の母平均には差が無い」
対立仮説(H1):「HTTP/2 と HTTP/1.1 の表示速度の母平均には差がある」
両側検定です。
検定統計量
HTTP/2 と HTTP/1.1 の表示速度をそれぞれ 30 回計測し、平均を計算します。
サンプルサイズはもっと大きくしたかったのですが、バーチャルマシンを借りる費用と、手作業で計測する私の集中力(^^;)を考慮すると、このくらいが限界です。
有意水準
5%(α=0.05)
以上の条件で、仮説検定を行います。
計測環境
サーバ
マシン:さくらのクラウド(石狩)1コア メモリ1GB + CentOS7.2
WEBサーバ:Apache2.4.20 + mod_http2
インストール手順
httpd.conf
httpd-ssl.conf
画像ファイル100枚(容量合計:1MB)を /usr/local/apache2/htdocs/ に配置して、各クライアントから表示速度を計測します。(計測に使ったコンテンツ)
クライアントのロケーション
- さくらのクラウド(石狩)
- フレッツ光(千葉)
- LTE(千葉)
- AWS(東京)
- AWS(バージニア北部)
計測方法
Chrome バージョン51 表示>開発/管理>デベロッパーツール の「Network」を選択して「Load」の値を計測(「Disable cache」をチェック)

計測の注意点
計測前に、Chromeを再起動すること。
Chromeの「シークレットモード」を使用すること。
「Disable cache」がチェックされていることを確認すること。
DNSルックアップなどの、オーバーヘッドを除去するため、計測前に HTTP/2 と HTTP/1.1 のページをそれぞれ3回読み込むこと。
「(1回目)HTTP/2 → HTTP/1.1 →(2回目)HTTP/2 → HTTP/1.1 → ...」のように、偏りが出ないように交互に計測すること。
さくらのクラウド(石狩)
サーバのロケーションと同じ、さくらのクラウド(石狩)から計測した結果です。おそらく同一データセンタ内に配置されています。
計測日時:2016-06-27 4:45 - 2016-06-27 4:56
マシン:1コア メモリ1GB + Windows Server 2012 R2
計測データ
sakura-ishikari-data.csv さくらのクラウド(石狩)単位:ms
散布図

箱ひげ図

仮説検定の結果
「p-value = 0.2381」> α=0.05 により、有意水準5%で、帰無仮説(H0):「HTTP/2 と HTTP/1.1 の表示速度の母平均には差が無い」が採択されました。
x = read.csv('sakura-ishikari-data.csv', header=T)
t.test(x$HTTP.2, x$HTTP.1.1, var.equal=F)
Welch Two Sample t-test
data: x$HTTP.2 and x$HTTP.1.1
t = -1.193, df = 53.577, p-value = 0.2381
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-48.43435 12.30101
sample estimates:
mean of x mean of y
431.8000 449.8667
フレッツ光(千葉)
自宅(千葉)のフレッツ光回線で計測した結果です。
計測日時:2016-06-26 7:05 - 2016-06-26 7:23
マシン:MacBook Air + OS X 10.11
計測データ
flets-chiba-data.csv フレッツ光(千葉) 単位:ms
散布図

箱ひげ図

仮説検定の結果
「p-value = 9.583e-09」< α=0.05 により、有意水準5%で、帰無仮説(H0)は棄却され、対立仮説(H1):「HTTP/2 と HTTP/1.1 の表示速度の母平均には差がある」が採択されました。
x = read.csv('flets-chiba-data.csv', header=T)
t.test(x$HTTP.2, x$HTTP.1.1, var.equal=F)
Welch Two Sample t-test
data: x$HTTP.2 and x$HTTP.1.1
t = -6.884, df = 49.477, p-value = 9.583e-09
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-242.6525 -133.0142
sample estimates:
mean of x mean of y
612.0000 799.8333
LTE(千葉)
LTE(iPhoneのテザリングを使用)回線で計測した結果です。
計測日時:2016-06-26 7:31 - 2016-06-26 7:40
マシン:Mac Book Air + OS X 10.11
計測データ
LTE-chiba.csv LTE(千葉) 単位:ms
散布図

箱ひげ図

仮説検定の結果
「p-value = 4.831e-11」< α=0.05 により、有意水準5%で、帰無仮説(H0)は棄却され、対立仮説(H1):「HTTP/2 と HTTP/1.1 の表示速度の母平均には差がある」が採択されました。
x = read.csv('LTE-chiba.csv', header=T)
t.test(x$HTTP.2, x$HTTP.1.1, var.equal=F)
Welch Two Sample t-test
data: x$HTTP.2 and x$HTTP.1.1
t = -9.1424, df = 37.124, p-value = 4.831e-11
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-609.3755 -388.2912
sample estimates:
mean of x mean of y
1277.500 1776.333
AWS(東京)
Amazon Web Services の東京リージョンから計測した結果です。
計測日時:2016-06-26 14:00 - 2016-06-26 14:26
マシン:t2.micro + Windows Server 2012 R2
計測データ
aws-tokyo-data.csv AWS(東京) 単位:ms
散布図

箱ひげ図

仮説検定の結果
「p-value < 2.2e-16」< α=0.05 により、有意水準5%で、帰無仮説(H0)は棄却され、対立仮説(H1):「HTTP/2 と HTTP/1.1 の表示速度の母平均には差がある」が採択されました。
x = read.csv('aws-tokyo-data.csv', header=T)
t.test(x$HTTP.2, x$HTTP.1.1, var.equal=F)
Welch Two Sample t-test
data: x$HTTP.2 and x$HTTP.1.1
t = -14.342, df = 54.973, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-220.0062 -166.0604
sample estimates:
mean of x mean of y
383.3333 576.3667
AWS(バージニア北部)
Amazon Web Services のバージニア北部リージョンから計測した結果です。
計測日時:2016-06-27 4:00 - 2016-06-27 4:16
マシン:t2.micro + Windows Server 2012 R2
計測データ
aws-us-east-1-data.csv AWS(バージニア北部) 単位:ms
散布図

箱ひげ図

仮説検定の結果
「p-value < 2.2e-16」< α=0.05 により、有意水準5%で、帰無仮説(H0)は棄却され、対立仮説(H1):「HTTP/2 と HTTP/1.1 の表示速度の母平均に差がある」が採択されました。
x = read.csv('aws-tokyo-data.csv', header=T)
t.test(x$HTTP.2, x$HTTP.1.1, var.equal=F)
Welch Two Sample t-test
data: x$HTTP.2 and x$HTTP.1.1
t = -43.149, df = 49.083, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1641.373 -1495.294
sample estimates:
mean of x mean of y
2253.000 3821.333
終わりに
ネットワーク的に遠くなるほど HTTP/2 の効果がよく分かりますね。


コメント
こんにちは。こちらの記事拝見させて頂きました。
コメントをご希望との事だったので、以下に記載させて頂きます。
・HTTP1.1とHTTP/2のプロトコルの速度比較をしたいのか、プロトコルのレイテンシの影響の比較をされたいのか?
実験の目的は明確に一つに定められるべきだと思います。
「ただし、サーバとクライアントのネットワークが極端に近い場合は、表示速度に違いはほとんどありません。」と、冒頭に書かれていますが、これが重要です。
プロトコルの速度を比較するためには、それ以外の変数を固定化する必要があります。
これが実験計画法におけるブロック化です。
商用の計測システムは、そこを担保するために、帯域保証の1次ISPの回線を利用して、回線の影響が及ばないようにします。それは、レイテンシという変数をできる限り固定化するためです。
私も、今回、httpvshttps.comのサイトの計測をサーバが置いてあるダラスで行ったのは、それが目的です。
レイテンシが上がるほどに、HTTP/2の方が有利になるのは、プロトコルの「特性」の話であって、「速度」の話ではないのです。
そして、回線のレイテンシについては、回線品質の問題であって、話題を分ける必要があります。
レイテンシの問題の解決は、HTTP/2以外にも色々アプローチがあり、それらの中の選択肢として検討されるべき事項で、プロトコルそのものの速度の評価とは別です。
・検定の手法の問題
「それぞれの分散の推定値が一致するとは考えづらく、対応のない2つの平均値の差の検定ですので『Welch(ウェルチ)の検定』を使うことにします。」とさらりと書いていらっしゃいますが、これは実務上、問題です。
検定されるのであれば、ちゃんとF検定はされるべきかと。
そして、何故、ウェルチの検定なのか?という問題もあります。
言い方を変えると、ここで「自由度を調整したt分布を使うべき理由」は何でしょうか?
ウェルチの検定が生まれた背景を学ばれた方が良いと思います。
等価自由度を使いたい、使わないといけないケースがあってこそのウェルチの検定なので、単純に「これはこうだから、この計算方法で」というのは、統計分析では禁じ手です。
もし検定されるのであれば、この場合は、スチューデントのt検定を使うべきです。
今回のデータの取り方は、単純無作為抽出ではないので、問題ありですが、それでも使えそうなデータ(さくらで計測したもの)でヒストグラムをつくれば、おおよそベルカーブを描いているのが確認できます。
今までの実務でも、単一のホストであれば、正規分布を描くことが分かっています。
あと、アプローチとして、簡単に等分散を放り出してはダメで、如何に、等分散化するかというアプローチが大事です。
それは、正規分布が統計学においては非常に強い理論だからです。
統計学は純粋数学とは違い、計算をすればいいというものではなく、その手法が生まれた背景や、その手法が使える限界を理解する必要があります。
「真の値とは何か?」という命題について、どのように考えていらっしゃるかです。
統計検定2級に合格されていらっしゃるので、記述統計と推測統計の違いはお分かりかと思います。
母平均の差の検定をするということは、推測統計、つまりモデルを作るというお話です。
神のみぞ知る、真の値を確率的に近づいて得るという話です。
「Webサイトパフォーマンスにおける真の値とは何であるのか?」というのは、師匠に相談して議論するのですが、まだ明確には定まっていません。自分の中では、こうだろうなというのが徐々に固まってきてはいます。
Webサイトパフォーマンスのデータは、
・経時データであり、時間帯・曜日・季節・年次のパターンがある
・サーバ、ネットワーク、クライアントと、構成要素それぞれの分散に影響を受けた合算値である(分散の加法性)
・通信をしているホスト毎の分散に影響を受け、全体としては、それらが合成されて、見た目が右に裾を引く非正規分布に見えるが、個別の分布は正規分布となる
という特徴があります。
上記を考えた上で、「プロトコルの配信速度の真の値とは何か?」という定義を考えて頂くと、レイテンシの影響を排除する件については「あぁ、そうか」とご納得頂けるかと。
他のコンテンツもちょこっと拝見しましたが、分析されたいドメインを定められて、その分野の師匠を見つけて学ばれると良いのではないかと思いました。
統計学は、ドメイン(分野)が異なると、思想も手法も異なります。
そして、本に書かれていないノウハウや知識がいっぱいあって、残念ながら、それらは検索ではほぼ見つかりません。先生について学ぶしかないです。
品質管理に興味をお持ちなのであれば、頻度主義の先生に師事されては如何でしょうか?
とりあえずは、永田靖先生の「サンプルサイズの決め方」や「入門実験計画法」を読まれることをお勧めします。
>竹洞 陽一郎様
ご丁寧なコメントを、誠にありがとうございます。
数々の至らない点のご指摘、大変勉強になりました。私は統計学を学び始めて1年になりますが、つくづく知識が浅いことを実感します。検定手法が生まれた背景を理解していないまま、安易に検定手法を選んでしまったことに反省です。
特に、後半の『「真の値とは何か?」という命題について〜』以降の部分は、全く意識していなかった内容でした。今後の統計学への取り組み方を考えてみたいと思います。